Taking into account data protection when designing the system
07 June 2024
To ensure that the development of an AI system respects data protection, it is necessary to carry out a prior reflection when designing it. This sheet details the steps involved.
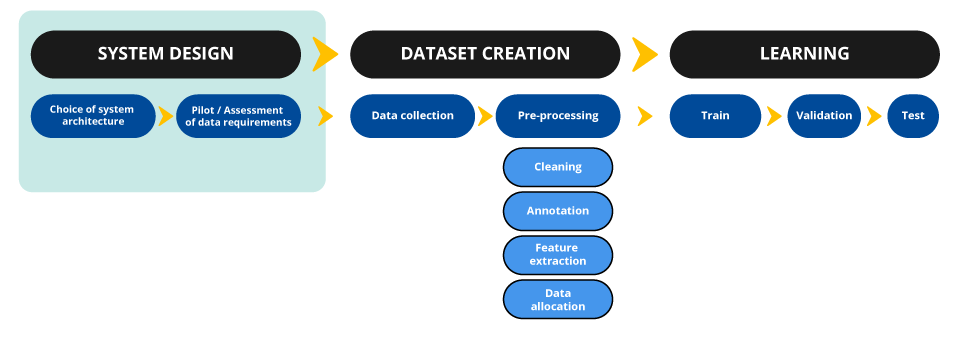
When considering the design choices of an AI system, the principles of data protection, and in particular the minimisation principle, must be respected. This approach takes place at four levels. A controller must therefore ask itself about:
- the objective of the system it wishes to develop;
- the method to be used which will affect the characteristics of the dataset;
- the data sources mobilized (see the how-to sheet on the compliance of the processing with the law, on open sources, on third parties, etc.) and among these sources, the selection of data strictly necessary, in view of the usefulness of the data and the potential impact their collection has on the rights and freedoms of data subjects;
- the validity of the choices previously made. Such validation may take different (non-exclusive) forms, such as a pilot study or the solicitation of an ethics committee.
The objective of the system
The aim of this step is to design, on the basis of the identified purpose (see how-to sheet 2 Defining a purpose), a system that complies with a specification, while limiting the potential consequences for the data subjects.
By specifying the use of the AI system in the deployment phase (whether implemented directly by the provider or by a third party), the system provider must determine:
- the type of expected results/outputs;
- acceptable performance indicators of the solution, whether quantitative (F1-score, mean squared error, computation time) or qualitative indicators (e.g. from human feedback);
- the context in which the system is used in order to identify priority information for its operational use;
- excluded contexts of use and information not relevant to the envisaged main use case(s) of the system.
Some AI techniques can allow for complex tasks that go beyond the initial objectives of the provider. By precisely defining the expected functionality, it is possible to avoid risks of over-collection.
The method to be used
Quite often, the same task can be carried out by different techniques. However, not all of them are equivalent, as they do not necessarily involve using the same data and the same amount. They may not make it possible to achieve the same level of performance, present more or less important challenges in terms of explainability, be subject to different operational constraints (such as the computational cost). While taking these issues into account, the system provider must select the technique most respectful of the rights and freedoms of individuals in order to respect the principle of data minimisation taking into account the objective pursued. In other words, if a technique performs the same function/allows to achieve the same result with less personal data, it must be preferred.
In particular, machine learning methods require generally the use of a very large amount of data. In order to ensure compliance with the principle of proportionality and data minimisation, the use of these technical solutions must therefore be justified. If there is a method that does not use machine learning and serves the objectives pursued, it must be preferred. Thus, the use of deep learning must be justified and should therefore not be systematic.
Semantic analysis of the content of a text could be carried out by a neural network based on annotated textual data, by an ensemble method such as a forest of decision-making trees or by an unsupervised algorithm, such as a clustering algorithm.
At the model training stage , account should also be taken of any uncertainty about the performance of a given architecture: compliance with the principle of minimisation shall be assessed on the basis of available scientific knowledge.
According to the advances in the concerned field, this reflection must be based on several factors for each of the architectures under consideration. This technical analysis can be done through:
- a state of the art, by means, for example, of:
- a study of scientific literature (census and study of academic or private publications, specialised conferences, etc.);
- a survey of the practices followed by professionals in the field: computer code open sourcing (including by placing it under a free license) of certain players in the sector may help to compare techniques;
- the solicitation of the community (online competitions or challenges, online forums, conferences and dedicated meetings, etc.);
- a comparison of the results obtained after the implementation of several architectures in the form of a ‘proof of concept’;
- a comparison of the results obtained from the use of an existing and pre-trained model (which may possibly require fine-tuning) and a model developed by the supplier.
While the choice of AI models and algorithms may limit data collection, other design choices should be taken into account, notably with regards to the privacy by design principle. The choice of the training protocol used, in particular, may make it possible to limit access to the data only to authorised persons, or to give access only to encrypted data. Two techniques, applicable in certain situations, are particularly interesting:
- Decentralised training protocols, such as federated learning, to which a LINC article has been dedicated. This technique makes it possible to train an AI model from several datasets kept separately and, thus, for each party in the chain to keep their hands on their data. However, this technique has certain risks, concerning the security of decentralised datasets, as well as trust between actors among whom a malicious actor could conduct a poisoning attack for example.
- The resources offered by cryptography. Recent scientific advances in the field of cryptography can provide strong safeguards for data protection. Depending on the use cases, it may, for example, be relevant to explore the possibilities offered by secure multiparty computation, or homomorphic encryption. The techniques used in this field make it possible to train an AI model on data that remains encrypted throughout the learning process. However, they remain limited in that they cannot be applied to all types of models and because of the additional computational cost they induce. In addition, some of them, such as homomorphic encryption for training neural networks, are still under development. As technical developments are frequent in this area, it is advisable to keep an active watch on this subject.
This list of measures is not exhaustive, additional measures could be cited such as the use of a trusted execution environment, differential privacy applied during the training phase or machine learning. More generally, due to the rapid evolution of the technology, it is recommended to conduct a technological watch on the privacy practices applicable when developing AI systems.
The selection of strictly necessary data
The principle
The principle of minimisation provides that personal data must be adequate, relevant and limited to what is necessary for the purposes for which they are processed. Particular attention must be paid to the nature of the data and this principle must be applied in a particularly rigorous manner when special categories of data are processed (within the meaning of Article 9 GDPR).
In practice
The principle of minimisation does not mean that it is forbidden to train an algorithm with very large volumes of data: it involves having a reflection before training so as not to resort to personal data that would not be useful for the development of the system. In order to identify the personal data necessary, four dimensions should be taken into account:
- Volume: number of data subjects, historical depth, accuracy of data, distribution of data according to situations and populations, etc. It may be justified, for example, by the limited computing capacities of the servers used for training, the needs in terms of representativeness of the dataset, the practices commonly accepted by the scientific community, a comparison of the results obtained by varying the volume of data, a statistical analysis demonstrating that a minimum amount of data is necessary to achieve significant results, etc.;
- Categories: age, gender, face image, social network activity, etc. The presence of special categories of data or highly personal data should be examined and justified (see how-to sheet 3, Determining the legal qualification of stakeholders). This analysis may be based on the need to train the model on counterfactual data (likely to give rise to false positives in practice), a study of the usefulness of the data categories concerned (see box below), etc. Among these categories of data, preference should be given to the least intrusive format without loss of information for the objective pursued, e.g. age or age range rather than a full date of birth;
- Typology: real, synthesised, augmented, simulation data, anonymised or pseudonymised data, etc.;
- Sources: as explained in the how-to sheet 3, Determining the legal qualification of stakeholders, identification of the data sources that are envisaged to be used, whether initial collection or re-use (data available in open source, previously collected by the provider or from data providers).
Although data selection is a generally necessary phase in order to design an AI system based on quality data, in some cases and in the alternative, it may be possible to process a dataset indiscriminately. The necessity will then have to be justified.
In addition to taking into account these technical dimensions, particular attention will have to be paid to the nature of the data within the meaning of the GDPR, and in particular in the case of sensitive or highly personal data.
Please note:
Issues relating to data distribution and representativeness should also be addressed at this stage. They are essential in order to minimise the risk of discriminatory biases.
Linked to this question, lies the one about the inclusion of “true negative” data in the training dataset (in particular for test and validation in order to verify the absence of certain edge cases).
As these questions are particularly important, a dedicated how-to sheet will later be published.
The validity of design choices
At the end of the previous three stages, design choices are theoretically validated and data collection can begin. In order to confirm the design choices quantitatively and qualitatively, several measures are recommended as good practice.
Conducting a pilot study
The objective of the pilot study is to ensure that the choices of a technical nature and those relating to the types of data identified are relevant. To do this, small-scale experimentations can be carried out. Fictitious, synthetic, anonymised or otherwise personal data collected in accordance with the GDPR may be used.
This type of experimentation does not always offer a representative view of the activity encountered on social networks, but it can be adapted to certain use cases such as the identification of hate content or the study of advertising targeting on these networks. This practice is beneficial because it offers a much higher level of transparency than certain practices such as web scraping.
The design of a film recommendation system
An organisation may collect from voluntary users the list of films viewed over a week and those viewed in the following days, either by declarative data or by collecting their viewing history on dedicated sites. It can conduct its pilot study on the data thus collected by anonymising the identifiers of each user.
Solicitating an ethics committee
The association of an ethics committee with the development of AI systems is a good practice to ensure that ethical issues and the protection of human rights and freedoms are taken into account upstream.
The ethics committee may have several tasks:
- the formulation of opinions on all or part of the organisation’s projects, tools, products, etc. which may be subject to ethical problems;
- the facilitation of reflection and the elaboration of an internal doctrine on the ethical aspects of the development of AI systems by the organisation (e.g. what conditions for subcontracting);
- the creation of guidance regarding collective and individual attitudes and the recommendation of certain principles, behaviours or practices.
The composition and role of this committee may vary depending on the situation, but several good practices are recommended. The ethics committee should:
- be multidisciplinary: the profiles of the members of the committee – employees of the organisation and/or external persons – must be diversified. Members contribute to the committee’s missions and can update issues that the development teams had not considered. A good practice is to assign certain committee seats to the employees of the organisation. In addition, the diversity of the members of the committee in terms of gender, age and ethnic and cultural origin is strongly encouraged;
- be independent: the opinions delivered by the committee may have important implications, for example for the commercial management of a company and thus favour or disadvantage some of its projects. Thus, the peoples in the committee must not be motivated by any gain (whether financial or other) to be derived from the decisions produced. Similarly, when employees sit on the committee, decisions rendered must not have consequences for them;
- have a clearly defined role: in order to ensure the systematic integration of the committee, a procedure must be established to determine the conditions under which the committee meets and must be associated. Depending on the situation, the committee may simply be advisory or adopt binding opinions: both approaches have advantages and disadvantages. If the committee delivers binding opinions, its inclusion in corporate governance must be particularly well defined in terms of the body’s statutes, in order to avoid its instrumentalisation. If the committee is advisory, its impact must be guaranteed, in particular by ensuring mandatory referral according to precise criteria and wide transparency of its opinions, at least within the organisation and possibly other measures such as the obligation for the project owner to reply in writing to the committee’s comments;
- be notified: the committee is encouraged to monitor technological and usage developments, document its opinions and share its knowledge. The risks associated with the use of AI evolve with technical development and new uses in this field, and it is necessary to keep a watch, in particular through the academic literature and publications of entities competent in this field (such as the Défenseur des Droits, or the French National Advisory Ethics Council for Health and Life Sciences). The dissemination of acquired knowledge will support advice and spread good practices.
In the case of the development of an AI system, the opinion of the ethics committee could be sought on several issues:
- Do the data used for development meet the ethical criteria of the organisation?
- Could the intended operational uses for the AI system have serious individual or societal consequences? Can these consequences be avoided? Can these operational uses be excluded?
- Could the potential misuse of the AI system (whether voluntary or accidental, in particular for open source models) have serious consequences for people or society? What measures would prevent them?
- Are the technical choices sufficiently controlled by the body (in the case of the use of radically new approaches)?
- Are transparency measures sufficient for the exercise of the rights of persons or to enable them to exercise a possible remedy?
- Are the risks of discriminations that may result from the use of the system identified and have the necessary means been put in place to avoid their occurrence?
- Is the organisation structured in such a way as to prevent risks by design (whether as regards non-discrimination, data protection, copyright protection, computer security, etc.)?
Depending on the size of the organisations and the way they are structured, it is not always possible to set up an ethics committee. Nevertheless, it is essential that such reflections can be carried out to support the development of AI systems. The appointment of an ‘ethics adviser’ may be an alternative which allows these questions to be taken into account.
