Quel est le périmètre des fiches pratiques sur l’IA ?
Quel est le périmètre des fiches pratiques sur l’IA ?
08 April 2024
La CNIL souhaite apporter des clarifications et des recommandations concrètes pour le développement des systèmes d’ (IA) et la constitution de bases de données utilisées pour leur apprentissage, qui impliquent des données personnelles. La CNIL définit le périmètre des différentes fiches pratiques.
Les fiches suivantes concernent uniquement la phase de développement de systèmes d’IA, et non celle de déploiement, lorsque celle-ci implique le traitement de données à caractère personnel (« données personnelles »). Elles se limitent aux traitements de données soumis au règlement général sur la protection des données (RGPD).
Ces fiches doivent permettre d’accompagner les professionnels aux profils aussi bien juridique que technique (délégués à la protection des données, professionnels du droit, personnes disposant de compétences techniques spécifiques ou non à l’IA, etc.).
À noter : ces fiches, adoptées à la suite d’une consultation publique, constituent un cadre qui permet d’accompagner les organismes dans leur mise en conformité. Elles rappellent les obligations posées par la règlementation et formulent des recommandations pour s’y conformer. Ces recommandations ne sont pas contraignantes : les peuvent s’en écarter, à condition de pouvoir justifier leur choix et sous leur responsabilité. Certaines recommandations sont également formulées à titre de bonnes pratiques et permettent d’aller plus loin que le respect de la règlementation.
La présence de données personnelles
Les fiches pratiques se rapportent aux activités de constitution de base de données et de leur utilisation dans le cadre du développement de systèmes d’IA lorsque toutes ou partie de ces données sont des données personnelles. Dans la pratique, trois cas peuvent être rencontrés :
Il est certain qu’aucune n’est présente dans la base de données : les fiches ne s’appliquent pas (même si certaines recommandations, de l’ordre de la bonne pratique, peuvent être pertinentes).
Il est certain que des données personnelles sont présentes : les fiches s’appliquent. C’est le cas des systèmes d’IA développés à partir de vidéos ou d’images de personnes, d’enregistrements de voix, de données personnelles structurées, etc. À noter que les textes européens posent la règle selon laquelle les jeux de données comprenant des données personnelles et non personnelles, dits « mixtes », sont régis par le RGPD, si les deux types de données sont inextricablement liés.
Il est possible que des données personnelles soient présentes : c’est un cas fréquent pour lequel la collecte de données personnelles n’est pas expressément souhaitée. Par exemple :
présence résiduelle de personnes ou de plaques d’immatriculation dans des images ;
occurrences de noms, prénoms, adresses, etc. dans des données textuelles de types commentaires ou prompt, etc.
Dans ces cas, sous réserve d’avoir anonymisé les données personnelles originales et pour les opérations de traitement ultérieures à cette suppression, les données perdent leur caractère personnel et les fiches ne s’appliquent plus.
par vérification manuelle, par exemple à l’occasion de l’annotation des données ;
par vérification automatique, par exemple par l’utilisation de techniques de détection de personnes/visages dans les images, par des méthodes de (named-entity recognition), etc.
Les questions relatives aux risques liés à l’utilisation du système feront l’objet de fiches publiées ultérieurement.
Les systèmes d'IA concernés
Les fiches pratiques de la CNIL concernent le développement de systèmes mettant en œuvre des techniques d’ impliquant un . Ceux-ci sont qualifiés de « systèmes d’IA ».
La définition des systèmes d’IA concernés par ces fiches pratiques est alignée avec celle du règlement européen sur l’IA.
Un est « un système automatisé conçu pour fonctionner à différents niveaux d'autonomie, qui peut faire preuve d'une capacité d'adaptation après son déploiement et qui, pour des objectifs explicites ou implicites, déduit, à partir des données d'entrée qu'il reçoit, la manière de générer des résultats tels que des prédictions, du contenu, des recommandations ou des décisions qui peuvent influencer les environnements physiques ou virtuels. »
En pratique, les systèmes d’IA concernés incluent les systèmes fondés sur l’ (supervisé, non supervisé, par renforcement) et ceux fondés sur la logique et les connaissances (bases de connaissance, moteurs d’inférence et de déduction, raisonnement symbolique, systèmes experts, etc.), ainsi que les approches hybrides.
Les fiches pratiques portent sur ces systèmes, que l’usage opérationnel en phase de déploiement soit défini dès la phase de développement, ou qu’il s’agisse de systèmes d'IA à usage général (« general purpose AI »), par exemple mettant en œuvre des modèles « de fondation », du fait de leur capacité à être réutilisés et adaptés pour différentes applications et cas d’usage.
Elles concernent également tous les systèmes d’IA tels que définis ci-dessus, que l’apprentissage soit par exemple réalisé « une fois pour toutes » ou en continu. Dans le cas des systèmes d’, les données collectées lorsque le système est déployé sont réutilisées pour l’amélioration itérative du système.
Enfin, elles concernent les traitements consistant à entraîner ou à ajuster (fine tuning/transfer learning) des modèles d'IA existants, indépendamment de leur intégration dans un système à proprement parler, dès lors qu’ils impliquent des données personnelles.
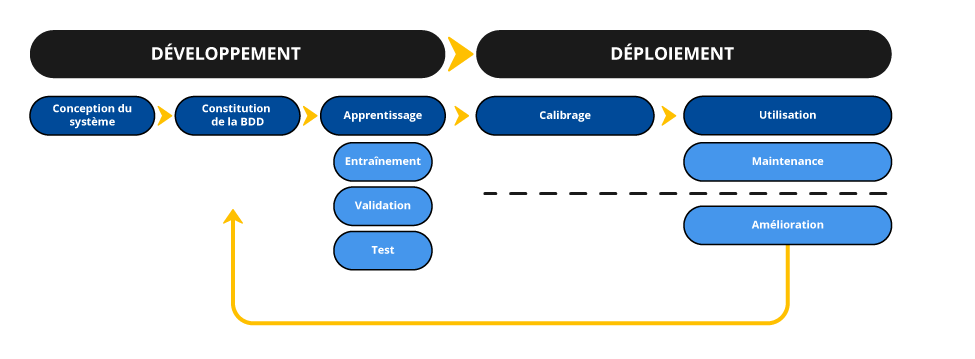
Comme illustré dans le schéma précédent, la mise en place d’un reposant sur l’ nécessite, en principe, la succession de deux phases distinctes :
la phase de développement : elle consiste à concevoir, développer et entraîner un système d’IA.
la phase de déploiement : elle consiste à mettre en usage le système d’IA développé lors de la première phase.
La phase de développement comprend toutes les étapes du développement du système d’IA jusqu’à son déploiement (phase de production), à savoir :
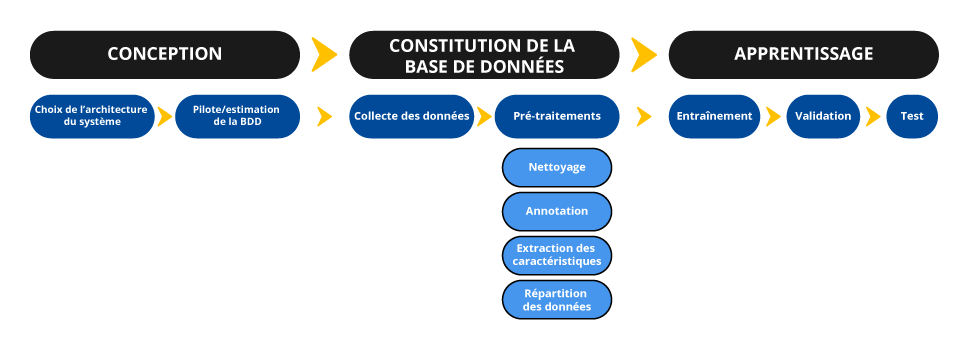
la conception du système : choix de l’architecture, dont la ou les méthodes d’apprentissage et le cas échéant la sélection de , identification des données nécessaires et premiers tests, pilotes ;
la constitution de la base de données : collecte et prétraitement (nettoyage, annotation, extraction de caractéristiques, répartition des données) ;
l’apprentissage : entraînement du modèle, éventuel ajustement ou fine-tuning), réglage et validation des hyperparamètres, tests de performance ;
et parfois, l’intégration : lorsque le produit final attendu à l’issue du développement est un système et non un modèle, insertion du modèle entraîné dans le système d’information, connexion aux autres composantes logicielles, développement d’une interface utilisateur, rédaction d’une documentation utilisateur, etc.
Représentation des différentes étapes du développement d'un système d'IA.
Conception : choix de l'architecture du système, estimation de la base de données. Constitution de la base de données : collecte des données, pré-traitements. Apprentissage : Entraînement, validation, test.
Dans de nombreux cas, le développement d’un système d’IA reposera sur l’ajustement de modèles pré-entraînés (« fine-tuning ») ou l’ (« transfer learning »). La CNIL considère que cette phase constitue une deuxième phase de développement, distincte de celle ayant permis la constitution du modèle d’origine.
Dans le cas de l’, les données sont collectées lors du déploiement et de la mise en production du modèle pour son amélioration future. L’entraînement en continu est donc inclus dans cette phase de développement via une boucle de rétroaction.
Il convient de noter que s’ajoutent à ces deux phases, une phase d’arrêt du système d’IA ou de suppression des données personnelles qu’il contenait. Les présentes fiches ne précisent pas les opérations à réaliser lors de cette phase, qui relèvent également de la réglementation sur la protection des donnés personnelles.
Textes applicables
Réglementation relative à la protection des données personnelles
Les fiches pratiques concernent, en particulier, les cas d’usages relatifs à la phase de développement d’un (recherche scientifique, recherche et développement, personnalisation d’un produit commercial, amélioration du service public rendu à l’usager, etc.) pour lesquels le RGPD est applicable.
Rappel sur le champ d’application du RGPD
Le RGPD s’applique à toute organisation :
publique et privée, quelle que soit sa taille (entreprise, administration, collectivité, association, etc.) ;
qui traite des données personnelles pour son compte ou non ;
établie sur le territoire de l'Union européenne dès lors que le traitement est effectué dans le cadre des activités d’un de ses établissements sur le territoire de l’Union, que le traitement ait lieu ou non dans l’Union ;
ou qui, non établie sur le territoire de l'Union européenne, cible directement des personnes physiques dans l’Union européenne ou opère un suivi de leur comportement.
Exemples :
Application du RGPD à la réutilisation de bases de données constituées hors de l’UE : le RGPD est applicable à la réutilisation de bases de données par un ou un établi dans l’Union européenne dès lors que le traitement est effectué dans le cadre des activités d’un de ses établissements sur le territoire de l’Union, même si ces bases de données ont été constituées hors de l’UE et qu’elles contiennent les données personnelles de personnes ne se trouvant pas sur le territoire de l’UE. Dans ce cas, le responsable du traitement est donc tenu de respecter la réglementation applicable en matière de protection des données.
Application du RGPD à la réutilisation de modèles entraînés hors de l’UE : le RGPD s’applique à l’utilisation des modèles entraînés hors de l’Union européenne par un responsable de traitement ou un sous-traitant établi au sein de l’Union européenne dès lors qu’ils contiennent des données personnelles et que le traitement est effectué dans le cadre des activités d’un de ses établissements sur le territoire de l’Union.
Les traitements de données en phase de développement du système d’IA soumis au champ de la directive « police-justice » ainsi que ceux qui intéressent la sûreté de l’État et la défense nationale sont donc exclus du périmètre de ces fiches. Toutefois, les recommandations des présentes fiches peuvent servir d’inspiration pour ces traitements.
Autres réglementations applicables
Si ces fiches visent à clarifier comment le développement de systèmes d’IA peut se conformer aux obligations en matière de protection de données personnelles, d’autres réglementations que ces fiches n’abordent pas directement sont susceptibles de s’appliquer. C’est par exemple le cas de la réglementation relative au droit de la propriété intellectuelle ou encore le règlement sur la gouvernance des données qui encadre notamment les services d'intermédiation de la donnée ou l’altruisme des données.
D’autres sont encore en cours d’élaboration. C’est en particulier le cas de la proposition de règlement européen sur l’IA qui a vocation à encadrer le développement et le déploiement de systèmes d’IA au sein de l’Union Européenne.
Enfin, des réglementations sectorielles s’appliquent aux systèmes d’IA développés ou déployés pour certaines applications soumises à une réglementation spécifique (santé, finance, systèmes critiques, etc.). Il appartient à chaque responsable de traitement de déterminer les réglementations applicables et de se tourner vers les régulateurs compétents.
Articulation des fiches avec le règlement sur l’IA
Le règlement européen distingue plusieurs catégories de systèmes selon leur niveau de risque au regard de la sécurité des produits et des droits fondamentaux : les systèmes interdits, les systèmes à haut risque, les systèmes nécessitant des garanties de transparence et les systèmes à risque minimal. Il prévoit ainsi différents degrés d’obligations reposant principalement sur les fournisseurs de systèmes d’IA.
Les présentes fiches ont été élaborées en vue d’une articulation intelligible avec ces futures obligations (par exemple en matière de qualification des acteurs et d’évaluation des risques).
Il est toutefois à noter que ces fiches s’appliquent, à droit constant, à tout traitement de données soumis au RGPD dans le cadre du développement d’un modèle ou d’un système d’IA, indépendamment de l’entrée en application des règles européennes sur l’. La CNIL rappelle, par ailleurs, que le règlement sur l’IA n’a pas vocation à remplacer les obligations en matière de protection des données mais bien à les compléter.
L’élaboration de règles plus précises sur l’articulation entre ces différentes exigences fait l’objet de travaux européens auxquels la CNIL participe activement et qui donneront lieu à des publications ultérieures.